Modifier Blocks
Chunk Block
Split a string into an array of strings based on token count
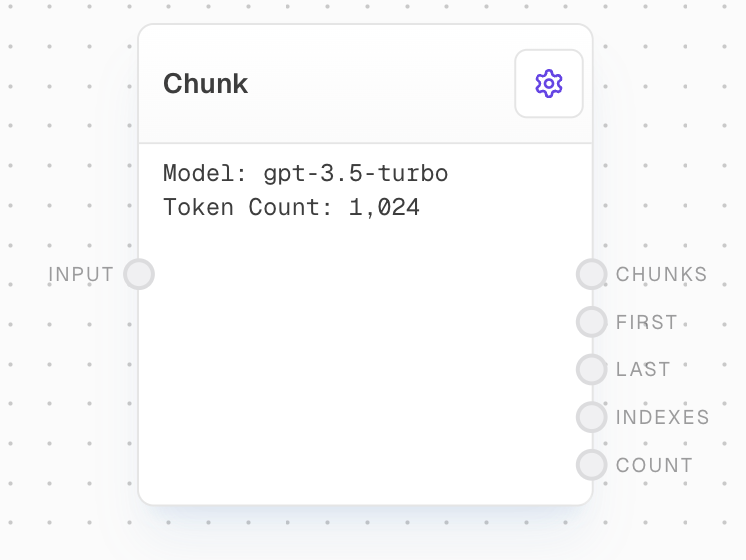

Overview
The Chunk Block is used to split a string into an array of strings based on a token count. This is particularly useful for handling large text inputs that exceed token limits in Language Models (LLMs), or for truncating strings to specific token counts.Inputs
The string to be split into chunks. Non-string inputs will be coerced to strings.
The AI model to use for tokenization. Only available when “Use Model Input” is enabled in settings.
Outputs
An array containing all the chunks after splitting the input string.
The first chunk from the chunks array. Useful for truncating text from the start.
The last chunk from the chunks array. Useful for truncating text from the end.
A list of sequential numbers starting from 1, one for each chunk. Useful for filtering or zipping with the chunks array.
The total number of chunks created.
Editor Settings
The model to use for tokenizing the text. Different models may tokenize text differently. Can be overridden by the “model” input if “Use Model Input” is enabled.
When enabled, adds a “model” input port that can override the “AI Model” setting.
The target number of tokens for each chunk. The actual chunk sizes may vary slightly to maintain text coherence.
The percentage of overlap between consecutive chunks. For example, with a 50% overlap and 1000 tokens per chunk, each chunk will share approximately 500 tokens with the next chunk. This helps maintain context between chunks.
Example: Chunking a Long Text
- Create a Text Block with a long piece of text.
- Add a Chunk Block and connect the Text Block to its input.
- Configure the desired token count and overlap in the settings.
- Run the flow. The text will be split into chunks based on your settings.
Error Handling
The Chunk Block will automatically coerce non-string inputs into strings. No other notable error handling behavior.FAQ
Why use chunking for LLMs?
Why use chunking for LLMs?
Chunking is useful to avoid hitting token count limits in LLMs. You can split a long string into multiple chunks, process each chunk separately, and then combine the results.
How does the overlap feature work?
How does the overlap feature work?
The overlap percentage determines how much text is shared between consecutive chunks. For example, with 1000 tokens per chunk and 50% overlap, each chunk will share approximately 500 tokens with the next chunk. This helps maintain context and coherence between chunks.